
PETR 代码详解
小记
看了很久的PETR源代码,后续磕盐工作以此文章为基础在上面更改,期望能顺利毕业。
本来很早就想边看边记录,但是一直以为博客的源文件没有迁移到主力本上,突然才发现上一篇4090时都迁过来了,感觉自己最近有些不在状态了,还是得开启学习记录,保持状态。
整体的代码流程
配置文件
使用了mmdet框架的代码结构,这里从头到尾把配置文件部分讲清楚,其中一些细节会同步放出定义源码讲解。
使用 petr_r50dcn_gridmask_p4.py 做解释。首先是配置加载和预先定义。
1 | _base_ = [ |
模型定义部分,这一部分是重点关注部分。
1 | model = dict( |
在模型的定义,最上层模型文件中 petr3d.py,提取特征时对输入进行了处理。
1 | def extract_img_feat(self, img, img_metas): |
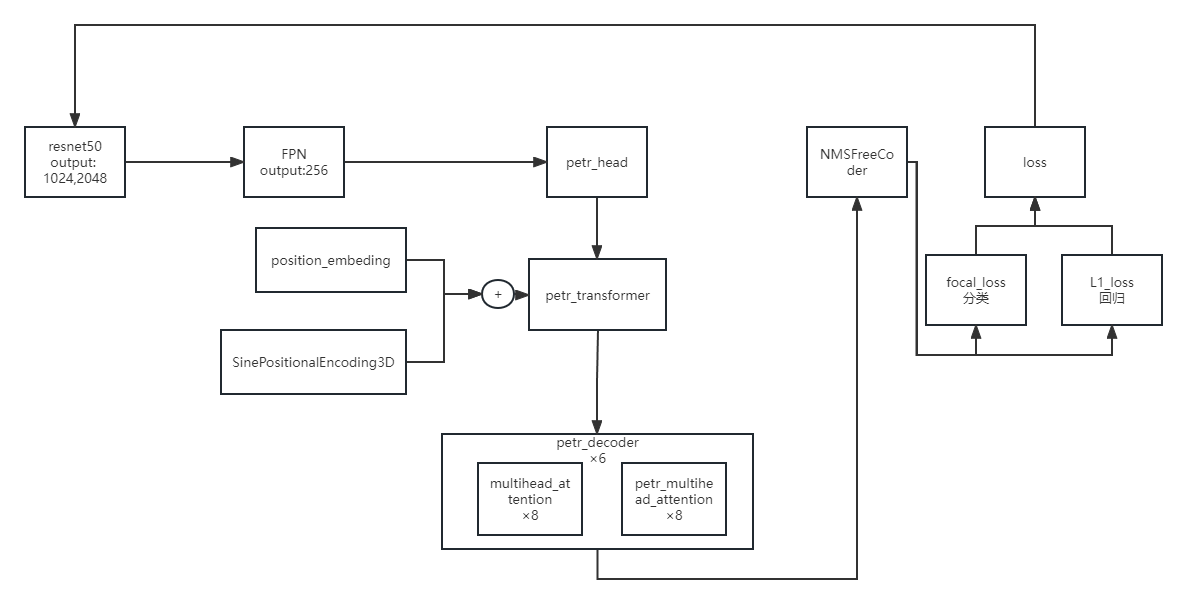
neck是FPN,不必多说。petr_head定义了decoder的结构,与DETR基本类似,主要不同就是PETR_head里面前向forward过程中的变化,这里先略过,先熟悉整体代码流程。
1 | img_neck=dict( |
到这里模型的定义基本完成,具体petr_head的细节在后面解释。positional_encoding是DETR中的位置编码,不是PETR的positional_embedding,positional_embedding的定义是在petr_head.py当中作为一个函数加进去的,后面会说。
1 | loss_cls=dict( |
这里是损失函数的定义使用的都是mmdet中自带的损失定义,Focalloss作为分类损失,L1和GIoU作为回归损失,匈牙利损失为Transformer的分类匹配损失。
下面是训练流程的配置,这里以前没有搞明白是做什么的,其实这里才是数据加载的重要过程,数据集的最终load进内存后进行预处理的过程是在这个pipeline当中完成的,要想知道输入给模型的数据是什么格式,是什么样的组织结构需要对这个地方有了解。
1 | train_pipeline = [ |
需要关注一下“LoadMultiViewImageFromFiles”这个过程
首先先来看一下数据集是如何定义的,在 nuscenes_dataset.py 中:
1 | class CustomNuScenesDataset(NuScenesDataset): |
可以看到输出的data信息只有图像的文件路径,并没有加载进内存。
在 loading.py中
1 | class LoadMultiViewImageFromFiles(object): |
这一部分看明白后,就可以知道送入$\color{Red} {backbone}$的数据为什么是(B,N,C,H,W)的维数了。backbone通过一次直接处理BN张(C,H,W)的图像数据,一次性的可以提取N个视角下的多目图像特征,在后续的encoder-decoder模块内可以学习到多个图像特征间的关联,实现特征融合。
最后的$\color{Red} {Collect3D}$步骤是将key内的元素提取出来。于是训练阶段的输入数据就包括了[‘gt_bboxes_3d’, ‘gt_labels_3d’, ‘img’]这三个内容。
数据集的配置部分,这里只是配置了数据集的一些基本情况,重点部分还是上面流水线与数据集的接口部分比较重要。
1 | dataset_type = 'CustomNuScenesDataset' |
剩下的部分就比较容易理解了,配置优化器和学习率等等,属于不需要较多改动的部分。
1 | optimizer = dict( |
PETR HEAD
我们先从最上层的PETR模型开始
petr.py
1 |
|
通过 backbone 提取特征后送入petr_head得到输出,和真值计算损失后输出一个训练损失,即为一个训练。
petr_head.py 这个文件中就完成了PETR对于DETR的改进部分和自己的创新点。理解PETR文章即为理解这一部分代码。
1 |
|
这里输出了所有检测到的目标。
position_embedding部分
1 | def position_embeding(self, img_feats, img_metas, masks=None): |