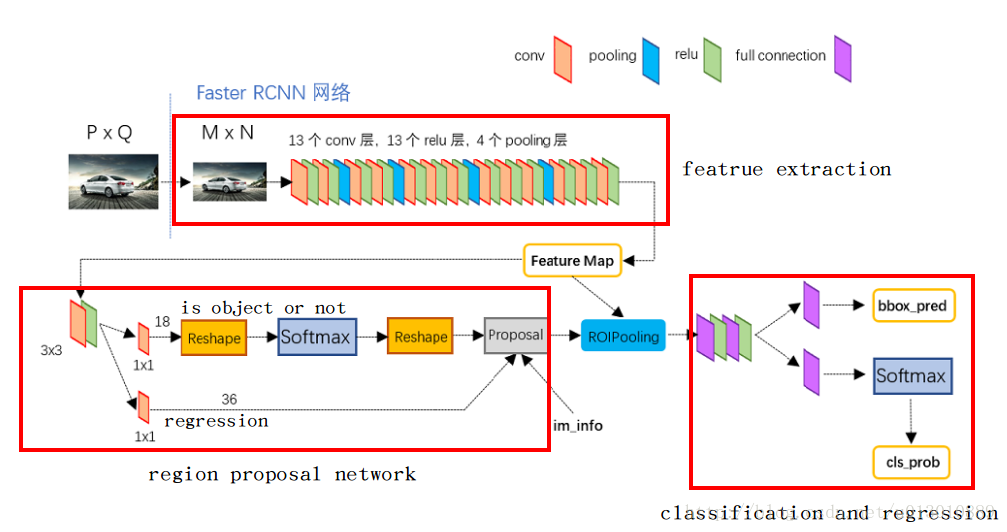
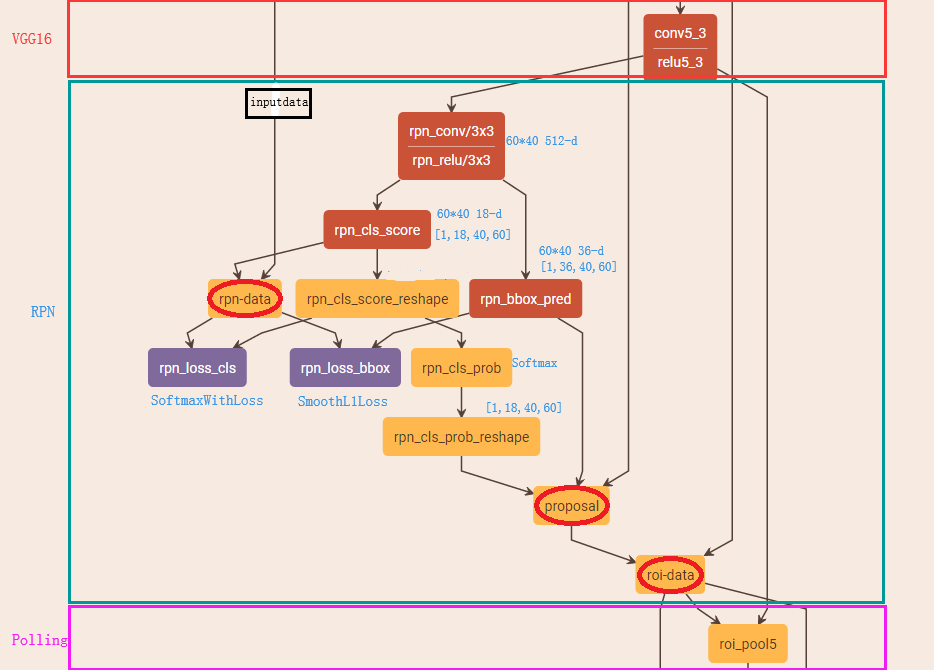
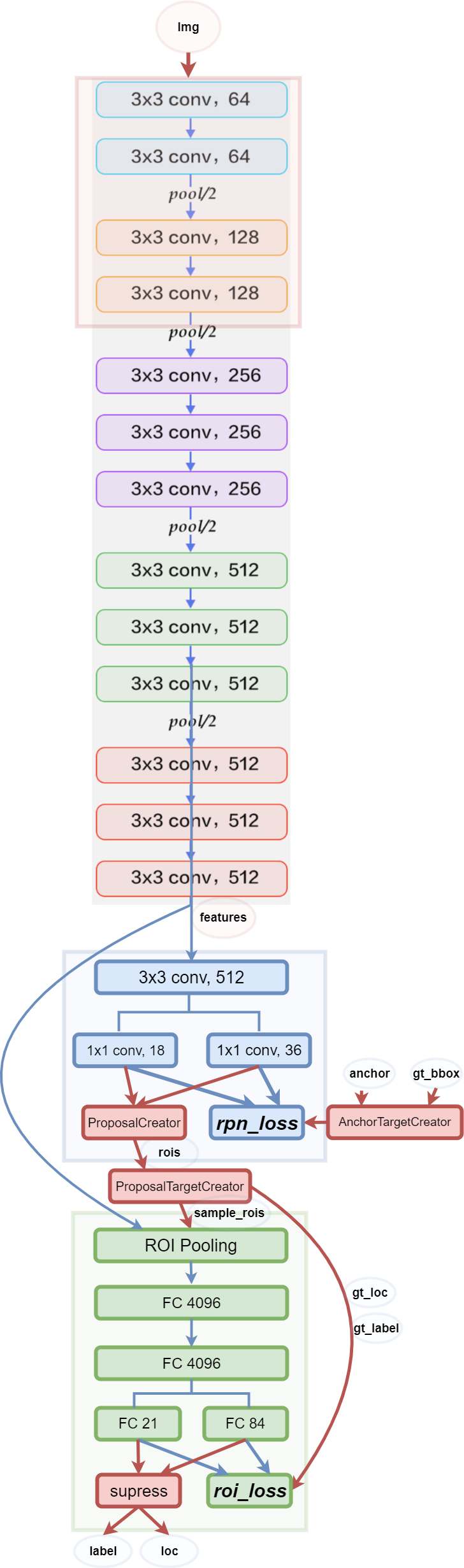
代码仓库来自:https://github.com/ruotianluo/pytorch-faster-rcnn
首先代码的结构为
本次重点记录一下最近看的基本网络结构,也就是加粗的部分
frcnn
layer_utils
roi_align
roi_pooling
预生成anchor的组件
**proposal_layer **
proposal_target_layer
anchor_target_layer
model
训练测试使用
nets
基本网络 network.py
resnet_v1.py
nms
roi_data_layer
utils
tools
network 的基本层次结构 init__(): 1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Network (nn.Module): def __init__ (self ): nn.Module.__init__(self) self._predictions = {} self._losses = {} self._anchor_targets = {} self._proposal_targets = {} self._layers = {} self._gt_image = None self._act_summaries = {} self._score_summaries = {} self._event_summaries = {} self._image_gt_summaries = {} self._variables_to_fix = {}
首先在骨架网络上,初始化时定义了一系列的字典,用来保存后续的一系列模型参数。等到后续网络继承这个基本结构后再给一些数据赋值,这个问题要明确。
forward(): 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def forward (self, image, im_info, gt_boxes=None , mode='TRAIN' ): self._image_gt_summaries['image' ] = image self._image_gt_summaries['gt_boxes' ] = gt_boxes self._image_gt_summaries['im_info' ] = im_info self._image = Variable(torch.from_numpy(image.transpose([0 ,3 ,1 ,2 ])).cuda(), volatile=mode == 'TEST' ) self._im_info = im_info self._gt_boxes = Variable(torch.from_numpy(gt_boxes).cuda()) if gt_boxes is not None else None self._mode = mode rois, cls_prob, bbox_pred = self._predict() if mode == 'TEST' : stds = bbox_pred.data.new(cfg.TRAIN.BBOX_NORMALIZE_STDS).repeat(self._num_classes).unsqueeze(0 ).expand_as(bbox_pred) means = bbox_pred.data.new(cfg.TRAIN.BBOX_NORMALIZE_MEANS).repeat(self._num_classes).unsqueeze(0 ).expand_as(bbox_pred) self._predictions["bbox_pred" ] = bbox_pred.mul(Variable(stds)).add(Variable(means)) else : self._add_losses()
再看传播函数,传入图片,标签,真值框等,然后进行保存。
再来看self._predict(): 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def _predict (self ): torch.backends.cudnn.benchmark = False net_conv = self._image_to_head() self._anchor_component(net_conv.size(2 ), net_conv.size(3 )) rois = self._region_proposal(net_conv) if cfg.POOLING_MODE == 'crop' : pool5 = self._crop_pool_layer(net_conv, rois) else : pool5 = self._roi_pool_layer(net_conv, rois) if self._mode == 'TRAIN' : torch.backends.cudnn.benchmark = True fc7 = self._head_to_tail(pool5) cls_prob, bbox_pred = self._region_classification(fc7) for k in self._predictions.keys(): self._score_summaries[k] = self._predictions[k] return rois, cls_prob, bbox_pred
_predict这个函数已经将frcnn的全部组件结合在了一起,所有的模块都在这里进行了整合,我们首先对整个网络做了一个全方位感性的认识,后面再着重理解各个模块的实现细节。
RPN层的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def _region_proposal (self, net_conv ): rpn = F.relu(self.rpn_net(net_conv)) self._act_summaries['rpn' ] = rpn rpn_cls_score = self.rpn_cls_score_net(rpn) rpn_cls_score_reshape = rpn_cls_score.view(1 , 2 , -1 , rpn_cls_score.size()[-1 ]) rpn_cls_prob_reshape = F.softmax(rpn_cls_score_reshape, dim=1 ) rpn_cls_prob = rpn_cls_prob_reshape.view_as(rpn_cls_score).permute(0 , 2 , 3 , 1 ) rpn_cls_score = rpn_cls_score.permute(0 , 2 , 3 , 1 ) rpn_cls_score_reshape = rpn_cls_score_reshape.permute(0 , 2 , 3 , 1 ).contiguous() rpn_cls_pred = torch.max (rpn_cls_score_reshape.view(-1 , 2 ), 1 )[1 ] rpn_bbox_pred = self.rpn_bbox_pred_net(rpn) rpn_bbox_pred = rpn_bbox_pred.permute(0 , 2 , 3 , 1 ).contiguous() if self._mode == 'TRAIN' : rois, roi_scores = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred) rpn_labels = self._anchor_target_layer(rpn_cls_score) rois, _ = self._proposal_target_layer(rois, roi_scores) else : if cfg.TEST.MODE == 'nms' : rois, _ = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred) elif cfg.TEST.MODE == 'top' : rois, _ = self._proposal_top_layer(rpn_cls_prob, rpn_bbox_pred) else : raise NotImplementedError
一开始,仔细看了代码,发现它的RPN层的输出并没有上面图片那样的softmax一下,而是直接使用前面的3x3卷积后的tensor简单进行了一下reshape然后将后面的维度当作了score。但是后面又想了想,在forward函数最后,return了一个add_loss(),也就是说,在这里面为RPN的cls_score增加了loss函数,所以之后反向传播的时候会根据这个函数在之前的1x1卷积中学习,使之得到二分类的分数。
网络的损失函数 _add_loss(): 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 def _add_losses (self, sigma_rpn=3.0 ): rpn_cls_score = self._predictions['rpn_cls_score_reshape' ].view(-1 , 2 ) rpn_label = self._anchor_targets['rpn_labels' ].view(-1 ) rpn_select = Variable((rpn_label.data != -1 ).nonzero().view(-1 )) rpn_cls_score = rpn_cls_score.index_select(0 , rpn_select).contiguous().view(-1 , 2 ) rpn_label = rpn_label.index_select(0 , rpn_select).contiguous().view(-1 ) rpn_cross_entropy = F.cross_entropy(rpn_cls_score, rpn_label) rpn_bbox_pred = self._predictions['rpn_bbox_pred' ] rpn_bbox_targets = self._anchor_targets['rpn_bbox_targets' ] rpn_bbox_inside_weights = self._anchor_targets['rpn_bbox_inside_weights' ] rpn_bbox_outside_weights = self._anchor_targets['rpn_bbox_outside_weights' ] rpn_loss_box = self._smooth_l1_loss(rpn_bbox_pred, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights, sigma=sigma_rpn, dim=[1 , 2 , 3 ]) cls_score = self._predictions["cls_score" ] label = self._proposal_targets["labels" ].view(-1 ) cross_entropy = F.cross_entropy(cls_score.view(-1 , self._num_classes), label) bbox_pred = self._predictions['bbox_pred' ] bbox_targets = self._proposal_targets['bbox_targets' ] bbox_inside_weights = self._proposal_targets['bbox_inside_weights' ] bbox_outside_weights = self._proposal_targets['bbox_outside_weights' ] loss_box = self._smooth_l1_loss(bbox_pred, bbox_targets, bbox_inside_weights, bbox_outside_weights) self._losses['cross_entropy' ] = cross_entropy self._losses['loss_box' ] = loss_box self._losses['rpn_cross_entropy' ] = rpn_cross_entropy self._losses['rpn_loss_box' ] = rpn_loss_box loss = cross_entropy + loss_box + rpn_cross_entropy + rpn_loss_box self._losses['total_loss' ] = loss for k in self._losses.keys(): self._event_summaries[k] = self._losses[k] return loss
小结 RPN在提取的特征上首先进行一个3x3卷积,有人说是进行语义空间的转换。然后使用1x1卷积分别进行二分类和位置回归。这里着重要明白这两个卷积就是进行分类和回归的操作,一开始我一直不理解这个卷积,还以为分类与回归的操作是后面使用某些fc层来实现的。其实,RPN就是一个全卷积的网络,这样对于输入的图片尺度没有了要求 (参考 )。
例如分类时使用的卷积核的通道数为9x2,每个像素点9个anchor,每个anchor进行二分类,使用交叉熵损失函数。回归时使用9x4个通道。
10.5更新
三个layer 在训练部分有三个layer,一开始一直搞不清楚各自的功能
_proposal_layer
这个layer在训练和预测时都会去使用,输入的是前面1x1卷积得到的预测的bbox位置(实际上是增量▲x,▲y,▲h,▲w等加到对应的anchor上),用来将人为定义的上万个anchor,根据nms等规则排除(定义的长宽阈值,前多少名的socre排序【score也是另一路1x1卷积得到的】,NMS,再次排名等),生成一定数量的rois,返回得到的roi和各roi的相应得分。
_anchor_target_layer
为每个gt分配anchor。用来判断所有的anchor属于前景还是后景,只在训练的时候使用。并且判断和gt的交并比,然后得到anchor的学习目标,个人理解是为了在后面的时候让anchor可以训练到回归位置。也就是上面所说的偏移量?(待证)
② 如果anchor box与ground truth的IoU值最大,标记为正样本,label=1
③ 如果anchor box与ground truth的IoU>0.7,标记为正样本,label=1
④ 如果anchor box与ground truth的IoU<0.3,标记为负样本,label=0
剩下的既不是正样本也不是负样本,不用于最终训练,label=-1
除了对anchor box进行标记外,另一件事情就是计算anchor box与ground truth之间的偏移量
令:ground truth:标定的框也对应一个中心点位置坐标x*,y和宽高w ,h*
anchor box: 中心点位置坐标x_a,y_a和宽高w_a,h_a
△x=(x*-x_a)/w_a △y=(y*-y_a)/h_a
△w=log(w*/w_a) △h=log(h*/h_a)
通过ground truth box与预测的anchor box之间的差异来进行学习,从而是 RPN网络中的权重能够学习到预测box的能力
_proposal_target_layer
为每个gt分配proposal。负责在训练RoIHead/Fast R-CNN的时候,从RoIs选择一部分(比如128个)用以训练,生成roi的label。同时给定bbox回归的训练目标, 返回(sample_RoI, gt_RoI_loc, gt_RoI_label)